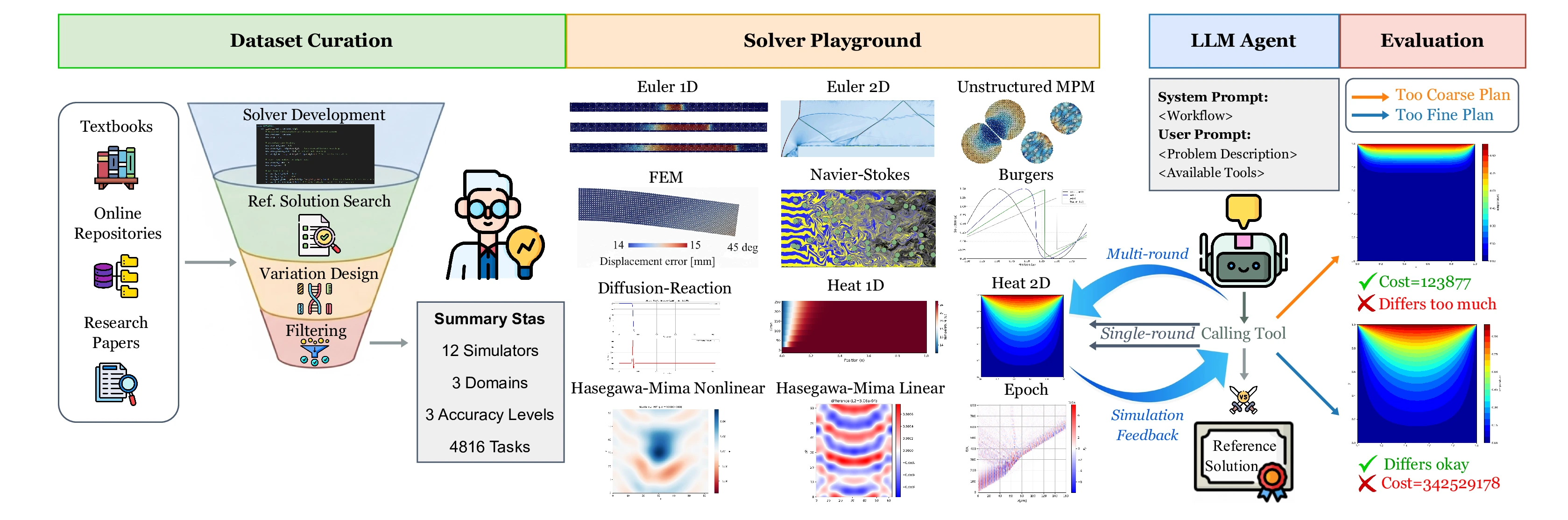
A Cost-Aware Benchmark for Automating Physics Simulations with LLMs
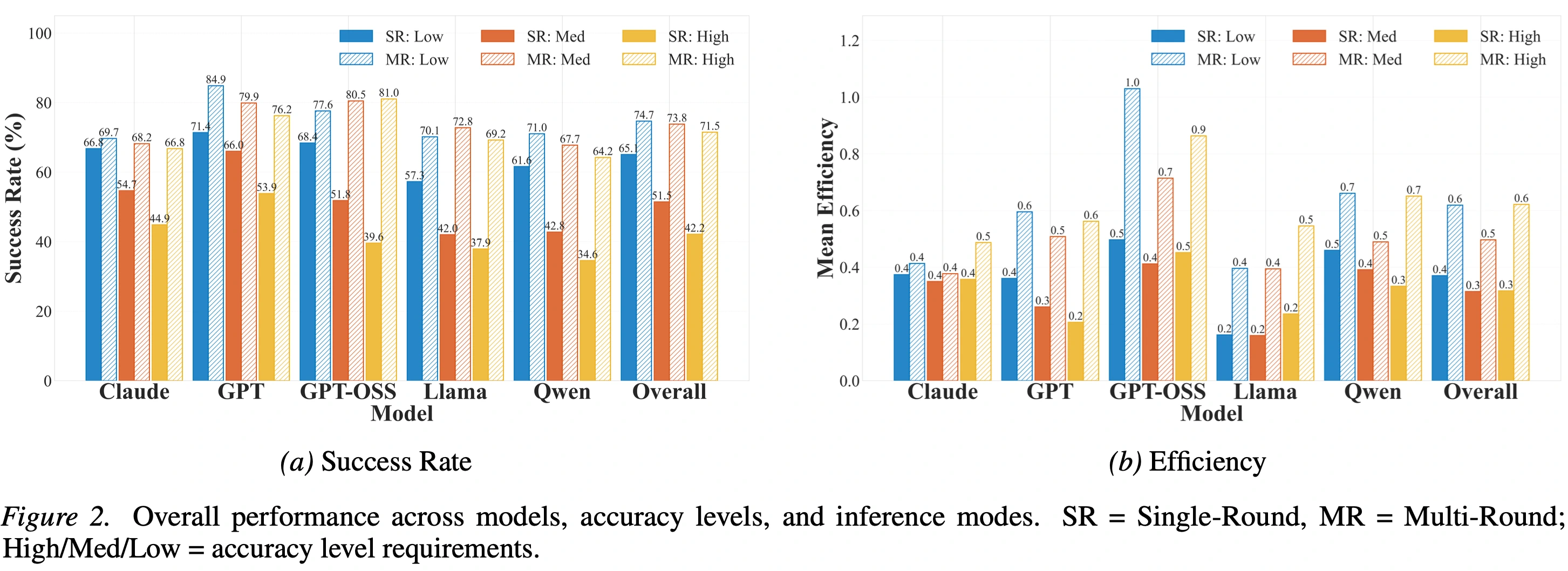
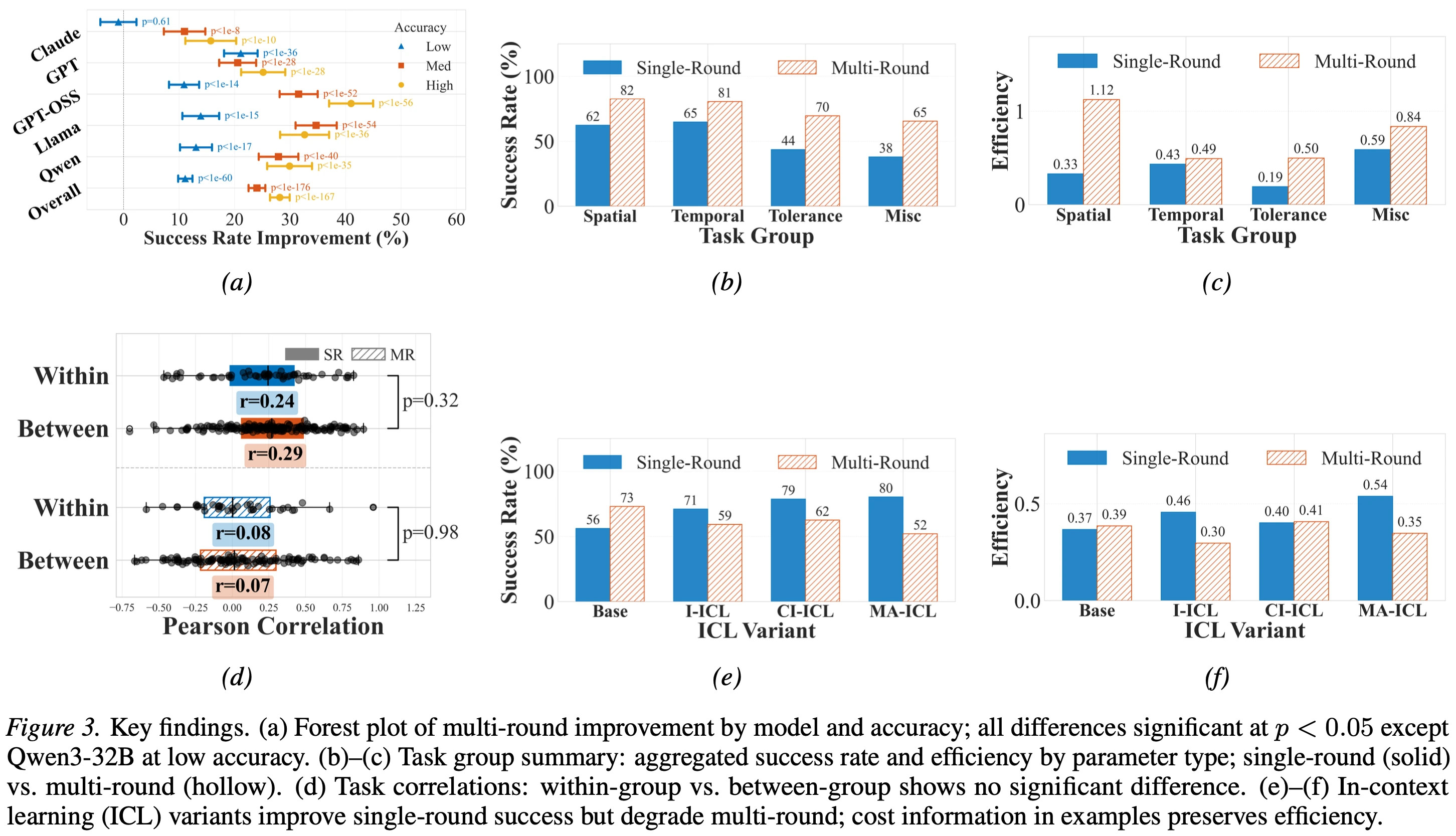
If you find SimulCost useful in your research, please cite our work:
@article{cao2026simulcost,
title = {SimulCost: A Cost-Aware Benchmark for Automating Physics Simulations with LLMs},
author = {Cao, Y. and Lai, S. and Huang, J. and Zhang, Y. and Lawrence, Z. and Bhakta, R. and Thomas, I. F. and Cao, M. and Tsai, C.-H. and Zhou, Z. and Zhao, Y. and Liu, H. and Marinoni, A. and Arefiev, A. and Yu, R.},
journal = {arXiv preprint arXiv:XXXX.XXXXX},
year = {2026}
}